voice_id. Supertone provides two kinds of voices, in separate endpoints:
- Preset voices — designed and provided by Supertone. Browse them in the Play voice library or via
GET /v1/voices. This page covers preset voices. - Custom voices — voice clones you create and manage yourself. See Custom voices.
Find a voice ID
Copy from Supertone Play (fastest)
Open the voice library in Supertone Play, hover any voice card, and click Copy voice ID. The ID is copied to your clipboard, ready to paste into a request.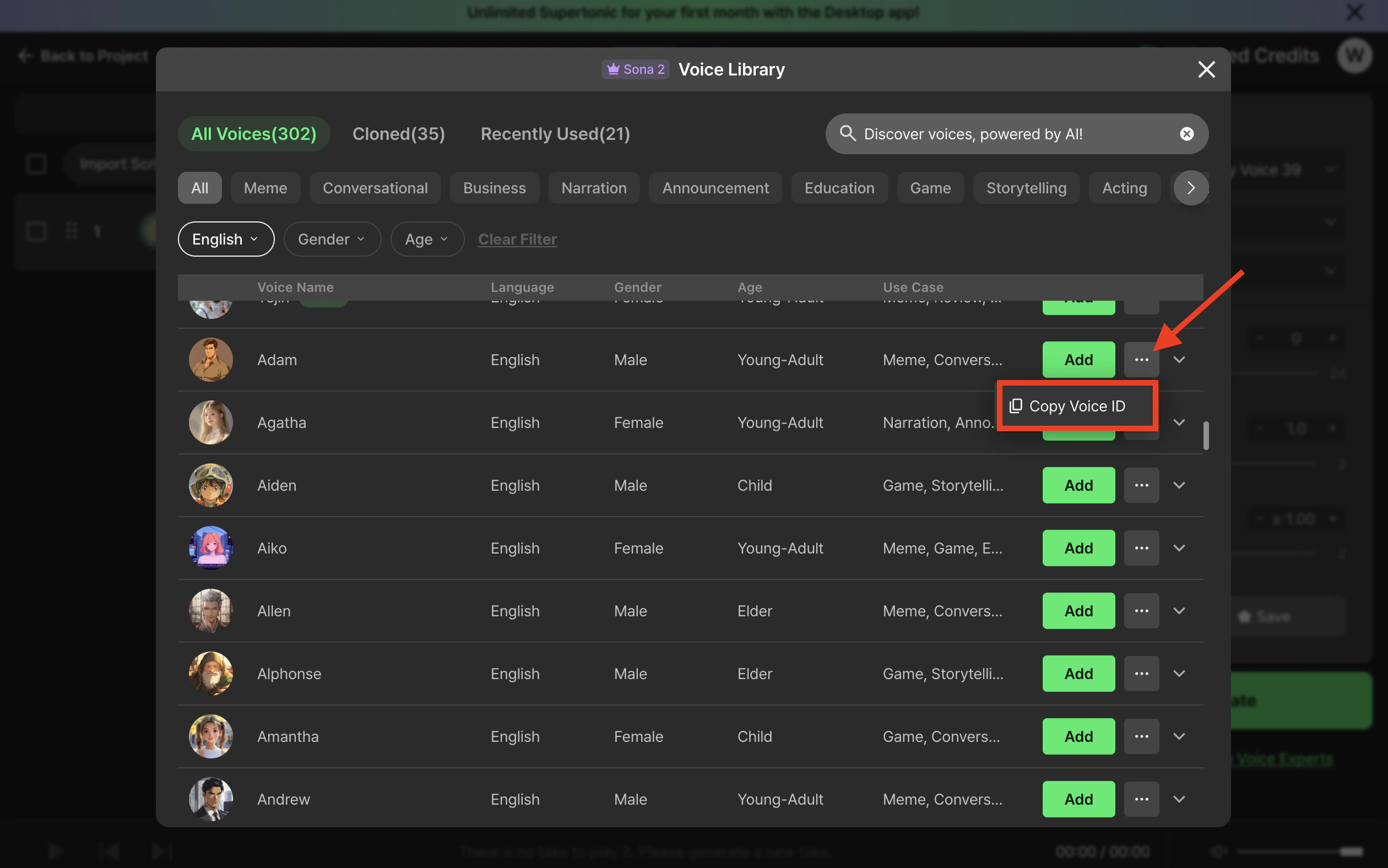
List voices via the API
- Python
- TypeScript
- cURL
Search by filters
Usesearch_voices to filter by language, style, gender, age, use case, or model. Multiple values are comma-separated and treated as OR conditions.
- Python
- TypeScript
- cURL
The voice object
Every voice returned by the API has roughly this shape:| Field | Meaning |
|---|---|
voice_id | The identifier to pass to TTS requests. |
language | Languages this voice supports. Your request language must be in this list. |
styles | Emotional styles available. The first entry is the default. |
models | Models the voice can be used with. |
samples | Pre-rendered preview clips per (language, style, model) combination — great for in-app previews. |
Important constraints
- All three must align. A successful TTS call needs a
voice_idplus a(language, style, model)combination that the voice actually supports. If the combination doesn’t exist, the API returns an error. - Default style. If you omit
style, the first value in the voice’sstylesarray is used. Different characters can have different defaults, so check the voice object before omitting. - Permissions. Preset voices are available to every account; access is gated only by your plan.
Next
Choose a model
Match voices to the right TTS model.
Custom voices
Clone and manage your own voices.